Data analysis/개념(Python)
pandas 치트시트를 활용한 기초 익히기
YoungBok
2022. 1. 12. 20:49
728x90
반응형
1. Pandas basic
import pandas as pd
2. DataFrame
df = pd.DataFrame(
{"a" : [4, 5, 6, 4],
"b" : [7, 8, 9, 9],
"c" : [10, 11, 12, 12]},
index = [1, 2, 3, 4])
df[실행결과]

* pd.DataFrame(shift+tab+tab)하면 자세한 설명창 나옴
3. Series
1) 벡터
df["a"] # 1차원의 자료구조(벡터)[실행결과]

2) 행렬
df[["a"]] # dataframe(행렬)[실행결과]

4. Subset
1) 행을 기준으로 값을 가져오기
df[df["a"] > 4][실행결과]

2) 열을 2개 이상 가져오기
df[["a", "b"]] # 2개 이상 가져올 때는 리스트 형식으로 가져옴[실행결과]

5. Summeraize Data
1) 빈도수 계산 - .value_counts()
df["a"].value_counts() # "a"열의 각각의 빈도수 구하기[실행결과]

2) 행 개수 구하기 - len("이름")
len(df)[실행결과] 4
6. Reshaping sort_values, drop
1) 컬럼 기준으로 정렬 - .sort_values()
df["a"].sort_values() # a 컬럼 기준으로 정렬[실행결과]

df.sort_values("a", ascending=False) # 전체를 a 컬럼 기준으로 역순으로 정렬[실행결과]

2) 해당 컬럼 제거 - .drop(["행/열 이름"], axis=0 or 1)
- axis=0 : 행 방향으로 drop
- axis=1 : 열 방향으로 drop
df = df.drop(["c"], axis=1) # 열을 기준으로 drop
df[실행결과]

7. Group Data
1) Groupby
df.groupby(["a"])["b"].mean() # a 컬럼으로 groupby하여 b의 평균값 구하기[실행결과]

df.groupby(["a"])["b"].agg(["mean", "sum", "count"]) # 집계연산[실행결과]

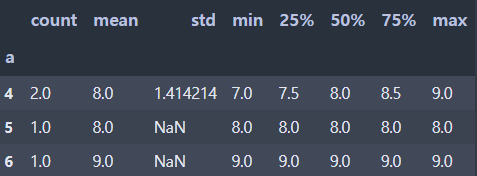
df.groupby(["a"])["b"].describe() # 데이터 요약[실행결과]
2) pivot_table(피벗할 데이터프레임, 행 위치에 들어갈 열, 열 위치에 들어갈 열, 데이터 집계 함수)
[기존 데이터프레임 df]

pd.pivot_table(df, index="a", values="b", aggfunc="sum") # aggFunc의 기본은 mean[실행결과]

8. Plotting
1) 선 그래프 - .plot()
df.plot()[실행결과]

2) 누적 면적 그래프 - .plot.area()
df.plot.area()[실행결과]

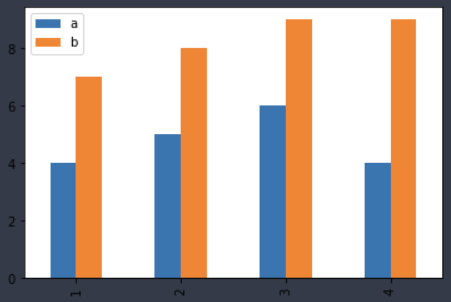
3) 막대 그래프 - .plot.bar()
df.plot.bar()[실행결과]
3) 밀도 그래프 - .plot.density()
df.plot.density()[실행결과]

* 강의영상 출처 : https://www.boostcourse.org/ds112/lecture/59933?isDesc=false
파이썬으로 시작하는 데이터 사이언스
부스트코스 무료 강의
www.boostcourse.org
728x90
반응형