해당 데이터는 KOSIS 국가통계포털 사이트에 접속하여 [인구]-[인구동향조사]-[출생]-'시군구/성/월별 출생' 클릭하여 시군구별은 '전국'을 선택하고 시점은 1997.01~2018.12로 설정하여 csv 파일 형식으로 다운받는다. (출처 영상 url은 아래)
KOSIS 국가통계포털
kosis.kr
전체 결과 코드 : https://github.com/vavana619/population-kosis
GitHub - vavana619/population-kosis
Contribute to vavana619/population-kosis development by creating an account on GitHub.
github.com
1. 통계청 출생아수 (시도/시/군/구)
pandas 라이브러리 불러오기
import pandas as pd
다운받은 csv 파일 데이터 불러와서(read_csv) 데이터의 개수(shape) 출력하기 (행, 열)
df_kosis = pd.read_csv("C:/data/population_kosis_1997_2018.csv", encoding="cp949")
df_kosis.shape(19, 793)
불러온 데이터를 미리보기(head)
df_kosis.head() # 미리보기
생략된 부분을 다 볼 수 있도록 설정하기
pd.options.display.max_columns = 793 # 생략된 columns을 다 볼 수 있음
df_kosis.head()
1) Tidy Data
: column에 있는 값을 행으로 녹이는 것을 의미한다. → melt(id_vars="행으로 보낼 column 이름")
"시군구별"을 행으로 보내서 Tidy data로 만들어주기
df = df_kosis.melt(id_vars="시군구별")
df.head()
"시군구별"의 행의 유일한 값 출력하기 -> unique()
df["시군구별"].unique()
값 중에서 "시군구별"의 "시군구별"은 필요없는 데이터이므로 제거하여 다시 df에 저장하여 전처리 전후 크기 비교
print(df.shape) # 전처리 전 행과 열의 수
df = df[df["시군구별"] != "시군구별"].copy() # "시군구별"이 아닌 데이터만 사용하여 다시 df에 저장
df.shape # 전처리 후 행과 열의 수(15048, 3)
(14256, 3)
-> 약 200개 정도 사라짐
해당 데이터가 사라졌는지 다시 확인
df["시군구별"].unique()
df.head()
- "variable"에 있는 데이터를 .을 기준으로 나눠서 연도/월/성별 column에 저장하기 -> str.split()[가져올 데이터 순서]
- expand=True : 결과를 데이터프레임 형태로 반환
- "성별"이 None인 것은 전체를 의미, 1은 남자, 2는 여자
df["연도"] = df["variable"].str.split(".", expand=True)[0] # .을 기준으로 문자를 나눠서 연도만 가져와서 저장
df["월"] = df["variable"].str.split(".", expand=True)[1] # .을 기준으로 문자를 나눠서 월만 가져와서 저장
df["성별"] = df["variable"].str.split(".", expand=True)[2] # .을 기준으로 문자를 나눠서 성별만 가져와서 저장
df.head()
df 데이터프레임 마지막 부분 미리보기로 확인
df.tail()
"성별"의 데이터 출력 (중복 X)
df["성별"].unique()array([None, '1', '2'], dtype=object)
-> 1과 2는 숫자가 아니라 문자형임!
nunique() : unique 함수로 출력된 데이터의 개수 (None은 제외한 개수)
df["성별"].nunique()2
"성별" column의 결측치(None)을 "전체"로 채우기 -> fillna("결측치 대신 넣을 값")
df["성별"] = df["성별"].fillna("전체")
df["성별"].unique()array(['전체', '1', '2'], dtype=object)
"성별" column에서 '1', '2'도 "남자", "여자"로 바꿔주기 -> replace("변경 전 값", "변경 후 값")
df["성별"] = df["성별"].replace("1", "남자").replace("2", "여자")
df["성별"].unique()array(['전체', '남자', '여자'], dtype=object)
"성별" column의 각 데이터의 합계 구하기 -> value_counts() (Series 데이터에만 적용이 가능함)
df["성별"].value_counts()
column 이름 변경하기 -> rename(columns={"변경 전 값", "변경 후 값"})
df = df.rename(columns={"variable":"기간", "value":"출생아수"})
df.head()
데이터프레임 요약결과 출력
df.info()
- "출생아수" 데이터가 object형이기 때문에 int형으로 변경 시도 -> astype(원하는 형태)
- 그러나, '-' 기호 데이터가 존재하여 오류 발생하므로 해당 데이터를 결측치로 변경 -> replace
- 결측치는 float형이기 때문에 "출생아수" 데이터를 float형으로 변경
# df["출생아수"].astype(int) # object형태를 숫자로 변경 -> 오류 (맨 밑출 참고)
df["출생아수"] = df["출생아수"].replace("-", np.nan) # 기호 -를 결측치로 변경
# df["출생아수"].astype(int) # 결측치는 float 타입이므로 강제로 정수로 바꿀 수 없음
df["출생아수"] = df["출생아수"].astype(float) # float 타입으로 변경
df["출생아수"].describe() # 요약하기
전국 출생아수를 가져와서 df_all에 담아서 미리보기
df_all = df[(df["시군구별"] == "전국") & (df["성별"] == "전체")]
df_all.head(2)
필요한 데이터(연도/월/출생아수)만 따로 모아서 다시 담기
df_all = df_all[["연도", "월", "출생아수"]].copy()
df_all.head()
2) 전국의 월별 출생아수
① Pandas로 시각화하기
시각화에 필요한 라이브러리 불러오고 폰트 설정(한글 깨짐 방지)
import matplotlib.pyplot as plt
plt.rc("font", family="Malgun Gothic") # Window 사용자
연도, 월별 출생아수 보기 -> set_index()로 dataframe의 인덱스를 지정하여 plot 그래프 그리기
df_all.set_index(["연도", "월"]).plot(figsize=(15, 4))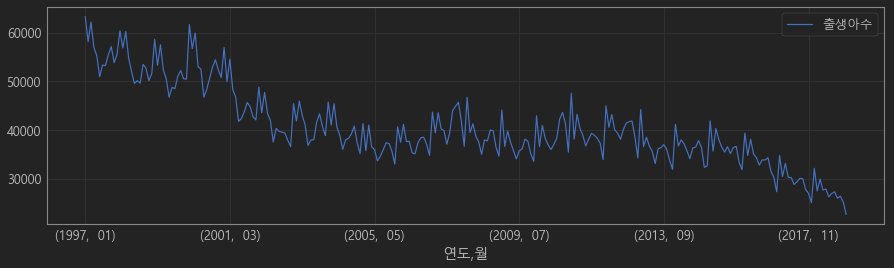
인덱스를 "연도"와 "월"로 정하고 최근 48개월에 대해서만 막대 그래프로 그리기
df_all[-48:].set_index(["연도", "월"]).plot.bar(figsize=(15, 4))
② Seaborn로 시각화하기
- Seaborn 라이브러리 가져오기
- 장점 : 통계적인 연산을 seaborn 내부에서 해줌
import seaborn as sns
- 1~12월 데이터에 대한 평균(기본값)을 구하여 선 그래프로 표현 -> lineplot()
- ci(그림자) : 값의 범위를 의미
plt.figure(figsize=(15, 4))
sns.lineplot(data=df_all, x="연도", y="출생아수", ci=None) # ci 그리지 않도록 설정
위 그래프를 월별로 다르게 표현하여 그리기 -> hue="월"
plt.figure(figsize=(15, 4))
sns.lineplot(data=df_all, x="연도", y="출생아수", ci=None, hue="월")
- 막대그래프로 그리기 -> barplot()
- ci(막대구간) : 신뢰구간을 의미
plt.figure(figsize=(15, 4))
sns.barplot(data=df_all, x="연도", y="출생아수", ci=None, hue="월")
2) 지역별 출생아수
"시군구별" column에서 "젼국"을 제외한 데이터만 df_local에 담기
df_local = df[df["시군구별"] != "전국"].copy()
df_local.head()
위에서 만든 데이터프레임을 "성별"로 다르게 표현하여 점 그래프로 그리기 -> pointplot()
plt.figure(figsize=(15, 4))
sns.pointplot(data=df_local, x="연도", y="출생아수", hue="성별")
전체 성별만 가져와서 df_local_all 변수에 담아서 미리보기
df_local_all = df_local[df_local["성별"] == "전체"]
df_local_all.head()
전체 성별을 pointplot으로 그리기
plt.figure(figsize=(15, 4))
sns.pointplot(data=df_local_all, x="연도", y="출생아수")
- "시군구별"로 다르게 표현하고 막대구간(신뢰구간) 그리지 않도록 설정하기
- 라벨을 그래프 밖에 그려지도록 설정하기
plt.figure(figsize=(12, 4))
sns.pointplot(data=df_local_all, x="연도", y="출생아수", hue="시군구별", ci=None)
plt.legend(loc='center right', bbox_to_anchor=(1.2, 0.5), ncol=1) # 라벨위치 조정
특정 데이터(서울특별시/경기도/세종특별자치시)만 보고싶을 경우
-> isin([]) 을 이용하여 특정 행만 추출하여 df_local_2에 저장
df_local_2 = df_local_all[df_local_all["시군구별"].isin(["서울특별시", "경기도", "세종특별자치시"])]
df_local_2.head()
위에서 생성한 df_local_2의 데이터로 pointplot 그리기
plt.figure(figsize=(15, 4))
sns.pointplot(data=df_local_2, x="연도", y="출생아수", ci=None, hue="시군구별")
- "세종특별자치시" 데이터만 따로 모아서 df_sj에 저장하기
- 2012년 이전에는 데이터가 존재하지 않기 때문에 결측치를 제거하고 저장 -> dropna()
- dropna(how="any") : 어떤 axis던지 하나라도 결측치가 존재하면 제거
- dropna(how="all") : 어떤 axis던지 모두 결측치가 존재하면 제거
- dropna(axis=0) : 행 방향 기준으로 결측치가 존재하면 제거
- dropna(axis=1) : 열 방향 기준으로 결측치가 존재하면 제거
df_sj = df[df["시군구별"] == "세종특별자치시"].dropna(how="any") # 하나라도 결측치가 있으면 제거하기
df_sj.head()
pointplot의 기본연산(default) 값은 mean(평균)이기 때문에 연산값을 sum으로 지정하여 연도별 합으로 그래프 그리기
-> estimator=np.sum
sns.pointplot(data=df_sj, x="연도", y="출생아수", ci=None, estimator=np.sum)
출처: https://www.youtube.com/watch?v=_Jb2O-1gIPY
'Data analysis > 실습 & 프로젝트' 카테고리의 다른 글
| [파이썬 데이터 분석 실무 테크닉 100] 1-2. 대리점 데이터를 가공하는 테크닉 10 (0) | 2022.05.28 |
|---|---|
| [파이썬 데이터 분석 실무 테크닉 100] 1-1. 웹에서 주문 수를 분석하는 테크닉 10 (0) | 2022.05.28 |
| K-beauty 온라인 판매분석 (0) | 2022.01.30 |
| 건강검진 데이터로 가설검정하기 (0) | 2022.01.27 |
| 서울 종합병원 분포 확인하기 (0) | 2022.01.26 |



